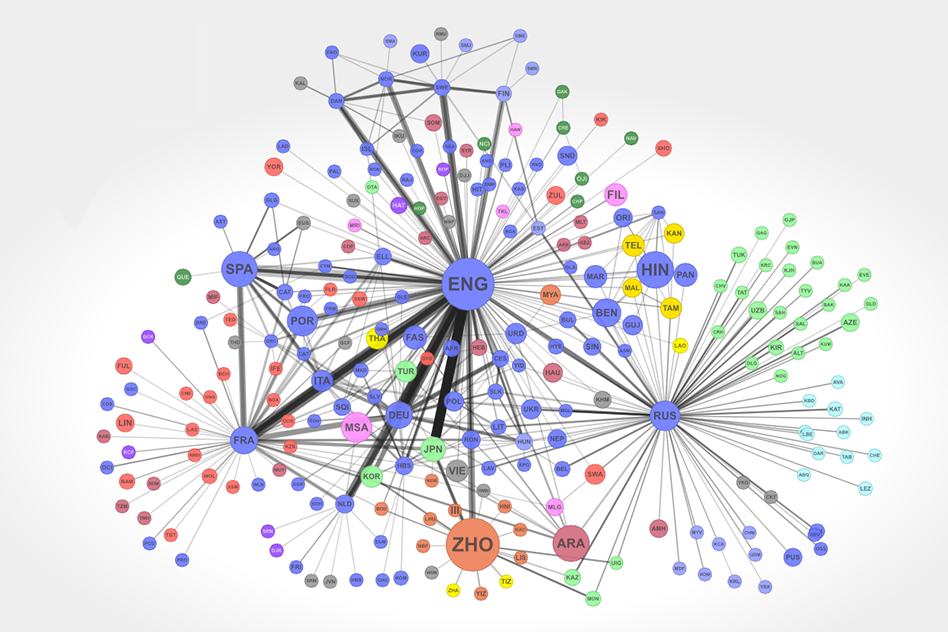

By analyzing data on multilingual Twitter users and Wikipedia editors and on 30 years’ worth of book translations in 150 countries, researchers at MIT, Harvard University, Northeastern University, and Aix Marseille University have developed network maps that they say represent the strength of the cultural connections between speakers of different languages.
This week, in the Proceedings of the National Academy of Sciences, they show that a language’s centrality in their network — as defined by both the number and the strength of its connections — better predicts the global fame of its speakers than either the population or the wealth of the countries in which it is spoken.
“The network of languages that are being translated is an aggregation of the social network of the planet,” says Cesar Hidalgo, the Asahi Broadcasting Corporation Career Development Assistant Professor of Media Arts and Sciences and senior author on the paper. “Not everybody shares a language with everyone else, and therefore the global social network is structured through these circuitous paths in which people in some language groups are by definition way more central than others. That gives them a disproportionate power and responsibility. On the one hand, they have a much easier time disseminating the content that they produce. On the other hand, as information flows through people, it gets colored by the ideas and the biases that those people have.”
Plotting polyglots
Hidalgo and his students Shahar Ronen — first author on the new paper — and Kevin Hu, together with Harvard’s Steven Pinker, Bruno Gonçalves of Aix Marseille University, and Alessandro Vespignani of Northeastern, included a given Twitter user in their data set if he or she had at least three sentence-long tweets in a language other than his or her primary language. That left them with 17 million of Twitter’s roughly 280 million users. They had similar thresholds for Wikipedia users who had edited entries in more than one language, which gave them a data set of 2.2 million Wikipedia editors.
In both cases, the strength of the connection between any two languages was determined by the number of users who had demonstrated facility with both of them.
The translation data came from UNESCO’s Index Translationum, which catalogues 2.2 million book translations, in more than 1,000 languages, published between 1979 and 2011. There, the strength of the connection between two languages was determined by the number of translations between them.
The researchers also used two different definitions of global fame. One was the measure that Hidalgo’s group had used in its earlier Pantheon project, which also looked at global cultural production. Pantheon had identified everyone with (at the time) Wikipedia entries in at least 26 languages — 11,340 people in all.
The other fame measure was inclusion among the 4,002 people profiled in the book “Human Accomplishment: The Pursuit of Excellence in the Arts and Sciences, 800 BC to 1950,” by the American political scientist Charles Murray. Murray’s list was based on the frequency with which people’s names were mentioned in 167 reference texts — encyclopedias and historical surveys — published worldwide.
Relative correlatives
There were, naturally, differences between the networks produced from the separate data sets and their correlations with the two fame measures. For instance, in the network produced from Wikipedia data, German is much more central than Spanish; in the Twitter network, the opposite is true.
Similarly, the network produced from UNESCO’s translation data correlated better with Murray’s fame index, which, as the subtitle of his book indicates, concentrated on science and the arts. The Wikipedia and Twitter networks correlated better with the Pantheon index, which included many more pop-culture figures.
But with both fame measures, at least one of the networks, taken in isolation, provided better correlation than the number of speakers of a language and the GDPs of the countries in which it is spoken. And when the networks were combined with population and income data, the correlations were higher still.
“We have to be very clear about what we’re talking about,” Hidalgo says. “This paper is not about global languages. All three networks are representative of elites. But those elites are the ones that drive the transfer of information across cultures.”
"This thought-provoking paper expands the intersection between big-data network science and linguistics," writes Kenneth Wachter, a professor of demography and statistics at the University of California at Berkeley. "It offers reproducible criteria for a language to serve as a global hub and is likely to stimulate many alternative perspectives."








